前言
在FPGA开发板中,实现PL端与PS端的通信是一个常见的话题。在这里,为实现PYNQ-Z2的PL与PS端通信,使用BRAM作为解决方案。
方案构想
这里参考了一个教程自定义IP实现PL处理PS输入数据(不过这个教程太坑了,过于理论,实际是有问题,稍后会提到),使用AXI BRAM Controller进行PS端的BRAM读写,创建一个AXI4 IP,进行PL端的读写。
这里硬件部分不作过多的讲述,详细的硬件部分可以参考上面的链接,但代码部分请使用本文提供的替代。
以下为方案实施
IP核的创建
我们将要创建一个IP核,功能是用于读取BRAM中的数据并加一后写回。
这里通过Create and Package new IP向导,创建一个新的AXI4 Peripheral,这里创建8个寄存器,寄存器可用于传递状态、简单数据,部分寄存器分别用于PS端传递在BRAM中的基地址、BRAM读开始信号、起始地址、数据长度、读写完成标识及PL端的操作完成标识,剩下的寄存器预留给以后的拓展,完成后选择Edit IP进入IP核的编辑。
IP核内容处理
我们需要添加一个可连接BRAM的端口用于PL端与BRAM的通信,因此在顶层文件中添加以下端口
output wire ram_clk , //RAM 时钟
input wire [31:0] ram_rd_data, //RAM 中读出的数据
output wire ram_en , //RAM 使能信号
output wire [31:0] ram_addr , //RAM 地址
output wire [3:0] ram_we , //RAM 读写控制信号
output wire [31:0] ram_wr_data, //RAM 写数据
output wire ram_rst , //RAM 复位信号,高电平有同时在模块中([你的IP核名称]_S00_AXI_inst)添加以上端口的实例化
.ram_clk (ram_clk ),
.ram_rd_data (ram_rd_data),
.ram_en (ram_en ),
.ram_addr (ram_addr ),
.ram_we (ram_we ),
.ram_wr_data (ram_wr_data),
.ram_rst (ram_rst )然后打开[你的IP核名称]_S00_AXI.v文件,实例化以下接口
bram_wr inst_bram_wr(
.clk (S_AXI_ACLK),
.rst_n (S_AXI_ARESETN),
.start_rd (slv_reg0[0]),
.start_addr (slv_reg1),
.rd_len (slv_reg2),
.pl_wr_done (pl_wr_done[0]),//用于传递PL操作完成标识
.ps_rd_start (slv_reg4),//用于传递PS开始读取标识
//RAM 端口
.ram_clk (ram_clk ),
.ram_rd_data (ram_rd_data),
.ram_en (ram_en ),
.ram_addr (ram_addr ),
.ram_we (ram_we ),
.ram_wr_data (ram_wr_data),
.ram_rst (ram_rst )
);并添加以下端口
output wire ram_clk , //RAM 时钟
input wire [31:0] ram_rd_data, //RAM 中读出的数据
output wire ram_en , //RAM 使能信号
output wire [31:0] ram_addr , //RAM 地址
output wire [3:0] ram_we , //RAM 读写控制信号
output wire [31:0] ram_wr_data, //RAM 写数据
output wire ram_rst , //RAM 复位信号,高电平有同时将Address decoding for reading registers下的slv_reg3修改为pl_wr_done,并在逻辑寄存空间下添加wire [C_S_AXI_DATA_WIDTH-1:0] pl_wr_done;以完成PL传递操作完成标识的连线。
最后创建一个新的wr_bram模块,添加以下内容
module bram_wr(
input clk , //时钟信号
input rst_n , //复位信号
input start_rd , //读开始信号
input [31:0] start_addr , //读起始地址
input [31:0] rd_len , //读数据的长度
output reg pl_wr_done , //pl端写出完毕
input ps_rd_start , //ps端开始读取
//RAM 端口
output ram_clk , //RAM 时钟
input [31:0] ram_rd_data, //RAM 中读出的数据
output reg ram_en , //RAM 使能信号
output reg [31:0] ram_addr , //RAM 地址
output reg [3:0] ram_we , //RAM 读写控制信号
output reg [31:0] ram_wr_data, //RAM 写数据
output ram_rst //RAM 复位信号,高电平有效
);
//reg define
reg [2:0] flow_cnt;
reg start_rd_d0;
reg start_rd_d1;
//wire define
//*****************************************************
//** main code
//*****************************************************
assign ram_rst = 1'b0;
assign ram_clk = clk ; //时钟clk
assign pos_start_rd = ~start_rd_d1 & start_rd_d0; //PL端操作开始信号
//延时两拍,采 start_rd 信号的上升沿
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
start_rd_d0 <= 1'b0;
start_rd_d1 <= 1'b0;
end
else begin
start_rd_d0 <= start_rd;
start_rd_d1 <= start_rd_d0;
end
end
//根据读开始信号,从 RAM 中读出数据
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
flow_cnt <= 3'd0;
ram_en <= 1'b0;
ram_addr <= 32'd0;
ram_we <= 4'd0;
end
else begin
case(flow_cnt)
3'd0 : begin
if(ps_rd_start) begin
flow_cnt <= 3'd0; //正在被ps端占用
end
else if(pos_start_rd) begin
ram_en <= 1'b1;
ram_addr <= start_addr;
flow_cnt <= flow_cnt + 3'd1;
end
end
3'd1 : begin
flow_cnt <= flow_cnt + 3'd1; //延迟一个时钟周期,原代码的修复一
end
3'd2 : begin
ram_we <= 4'b1111;
ram_wr_data <= ram_rd_data + 32'd1; //内容加一并写回
flow_cnt <= flow_cnt + 3'd1;
end
3'd3:begin
if(ram_addr - start_addr == rd_len - 4) begin //数据读完
flow_cnt <= flow_cnt + 3'd1;
ram_we <= 4'b0000;
end
else begin
ram_addr <= ram_addr + 32'd4; //地址累加 4
ram_we <= 4'b0000; //BRAM写入信号拉低,原代码的修复二
flow_cnt <= flow_cnt - 3'd2;
end
end
3'd4 : begin //完成状态
ram_addr <= 32'd0; //地址还原为0
flow_cnt <= 3'd5;
ram_en <= 1'b0; //取消bram使能
pl_wr_done <= 1'b1; //PL端完成标识
end
3'd5 : begin //传递PL端完成标识
if (ps_rd_start) begin //PS端开始读取,完成PL端所有操作
flow_cnt <= 3'd0;
pl_wr_done <= 1'b0;
end
else begin
flow_cnt <= 3'd5; //PS端开始读取,PL端所有操作完成
end
end
endcase
end
end
endmodule
接下来,我们需要在Package IP中先点击File Groups然后应用文件变更,之后在Ports and Interfaces中添加一个Interface,General、Port Mapping、Parameters分别按下图方式设置
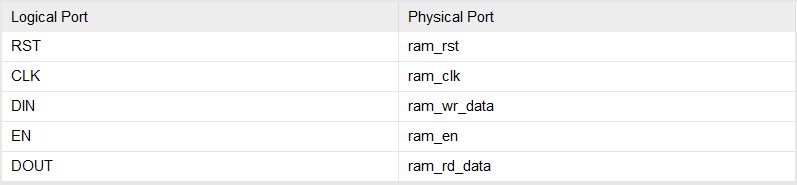

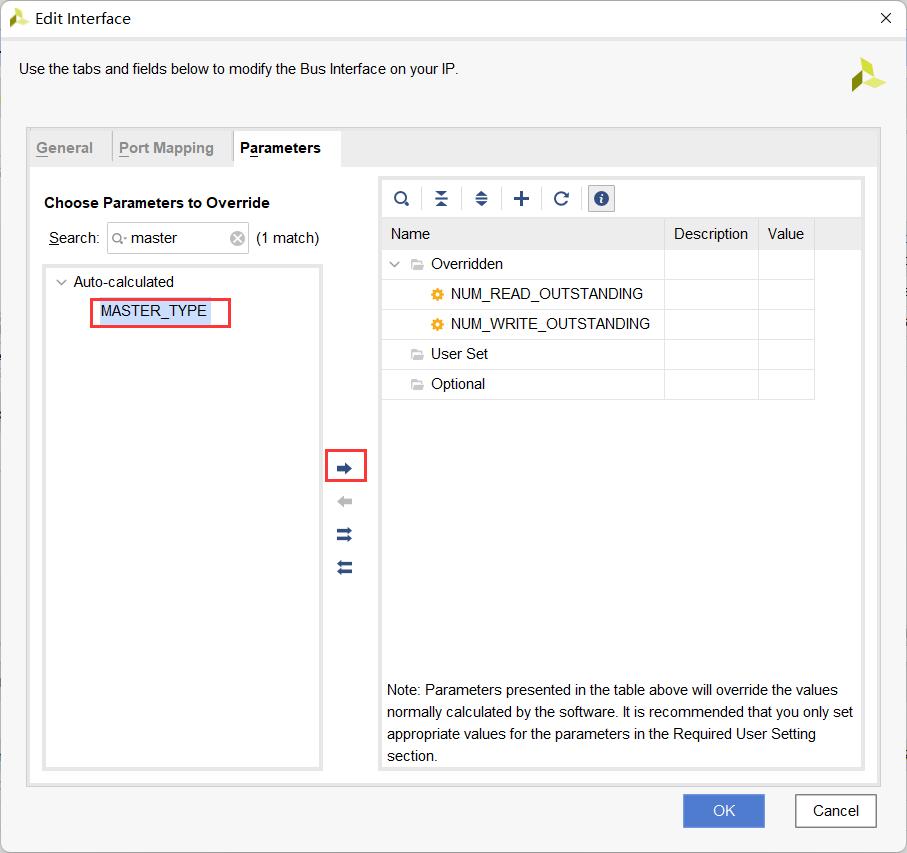
现在Repackage ip,IP核设计至此完成。
测试该IP核
为做一个简单的Testbench,这里进行如图的设计,原生的AXI BRAM Controller用于PS端BRAM读写,自定义IP核用于PL端的操作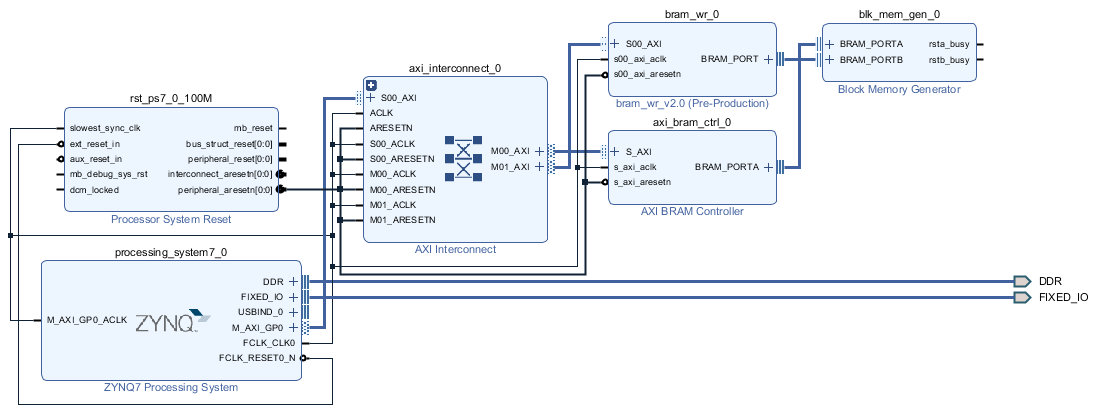
然后生成顶层、创建HDL Wrapper之后生成比特流并导出硬件,硬件部分至此完成。
SDK部分
创建一个新的Application Project,并使用C语言编写,可以创建一个hello world示例,并使用以下TestBench粘贴替换
#include "xil_printf.h"
#include "stdio.h"
#include "bram_wr.h"
#include "xbram.h"
#include "xparameters.h"
#define PL_BRAM_BASE XPAR_BRAM_WR_0_S00_AXI_BASEADDR //PL_RAM_RD 基地址
#define PL_BRAM_START BRAM_WR_S00_AXI_SLV_REG0_OFFSET //RAM 读开始寄存器信号
#define PL_BRAM_START_ADDR BRAM_WR_S00_AXI_SLV_REG1_OFFSET //RAM 起始寄存器地址
#define PL_BRAM_LEN BRAM_WR_S00_AXI_SLV_REG2_OFFSET //PL 读 RAM 的深度
#define START_ADDR 0 //RAM 起始地址 范围:0~1023
#define BRAM_DATA_BYTE 4 //BRAM 数据字节个数
int data[1024]; //写入 BRAM 的字符数组
int data_len; //写入 BRAM 的字符个数
//main 函数
int main()
{
int i=0,wr_cnt = 0,k=0;
int read_data=0, rd_data;
for(int k=0;k<1024;k++)
{
data[k] = k;
}
data_len = 1024;
//将用户输入的字符串写入 BRAM 中
getchar();//方便调试
//每次循环向 BRAM 中写入 1 个整数(4字节宽度)
for(i = BRAM_DATA_BYTE*START_ADDR ; i < BRAM_DATA_BYTE*(START_ADDR + data_len) ;i += BRAM_DATA_BYTE)
{
XBram_WriteReg(XPAR_BRAM_0_BASEADDR,i,data[wr_cnt]);
wr_cnt++;
}
//设置 BRAM 写入的字符串长度
BRAM_WR_mWriteReg(PL_BRAM_BASE, PL_BRAM_LEN , BRAM_DATA_BYTE*data_len);
//设置 BRAM 的起始地址
BRAM_WR_mWriteReg(PL_BRAM_BASE, PL_BRAM_START_ADDR, BRAM_DATA_BYTE*START_ADDR);
//拉高 BRAM 开始信号
BRAM_WR_mWriteReg(PL_BRAM_BASE, PL_BRAM_START , 1);
//拉低 BRAM 开始信号
BRAM_WR_mWriteReg(PL_BRAM_BASE, PL_BRAM_START , 0);
//从 BRAM 中读出数据
//检查可读状态
while(BRAM_WR_mReadReg(XPAR_BRAM_WR_0_S00_AXI_BASEADDR, 12)==0){
printf("not_ready\n");
}
i = 0;
printf("done");//可读
//ps读开始
BRAM_WR_mWriteReg(PL_BRAM_BASE, 16 , 1);
//拉低信号,pl端恢复状态
BRAM_WR_mWriteReg(PL_BRAM_BASE, 16 , 0);
//循环从 BRAM 中读出数据
for(i = BRAM_DATA_BYTE*START_ADDR ; i < BRAM_DATA_BYTE*(START_ADDR + data_len) ;i += BRAM_DATA_BYTE)
{
read_data = XBram_ReadReg(XPAR_BRAM_0_BASEADDR,i) ;
printf("BRAM address is %d\t,Read data is %d\n",i/BRAM_DATA_BYTE ,read_data) ;
}
}至此,所有工作完成,可以烧写比特流并运行查看效果
效果演示
PS端向BRAM中写入一个0-1023的递增数列,PL端遍历BRAM,将读入的数据加一并写回,得到以下结果。
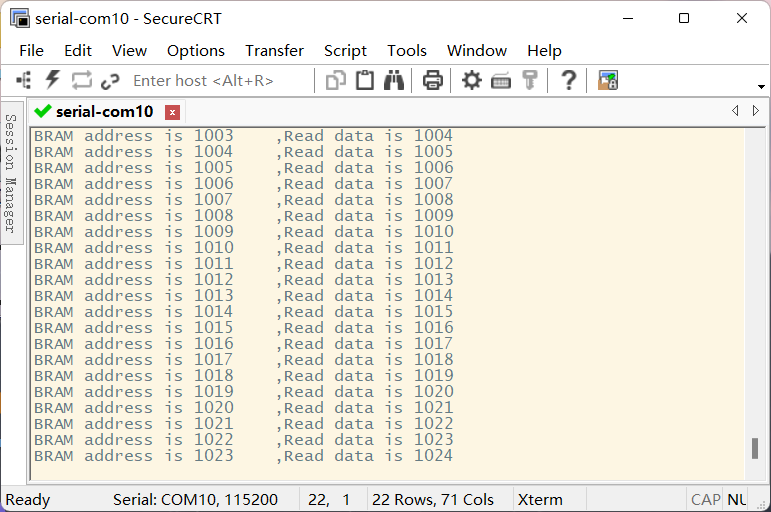
ILA使用及原博主代码错误
这里使用原作者提供的代码,然后在自定义IP核中,使用IP Catalog,搜索ILA,并添加ILA (Integrated Logic Analyzer),根据自己想debug的端口数,修改Number of Probes,并修改另一标签页的Probe宽度以对应debug的端口,以下是我的设置
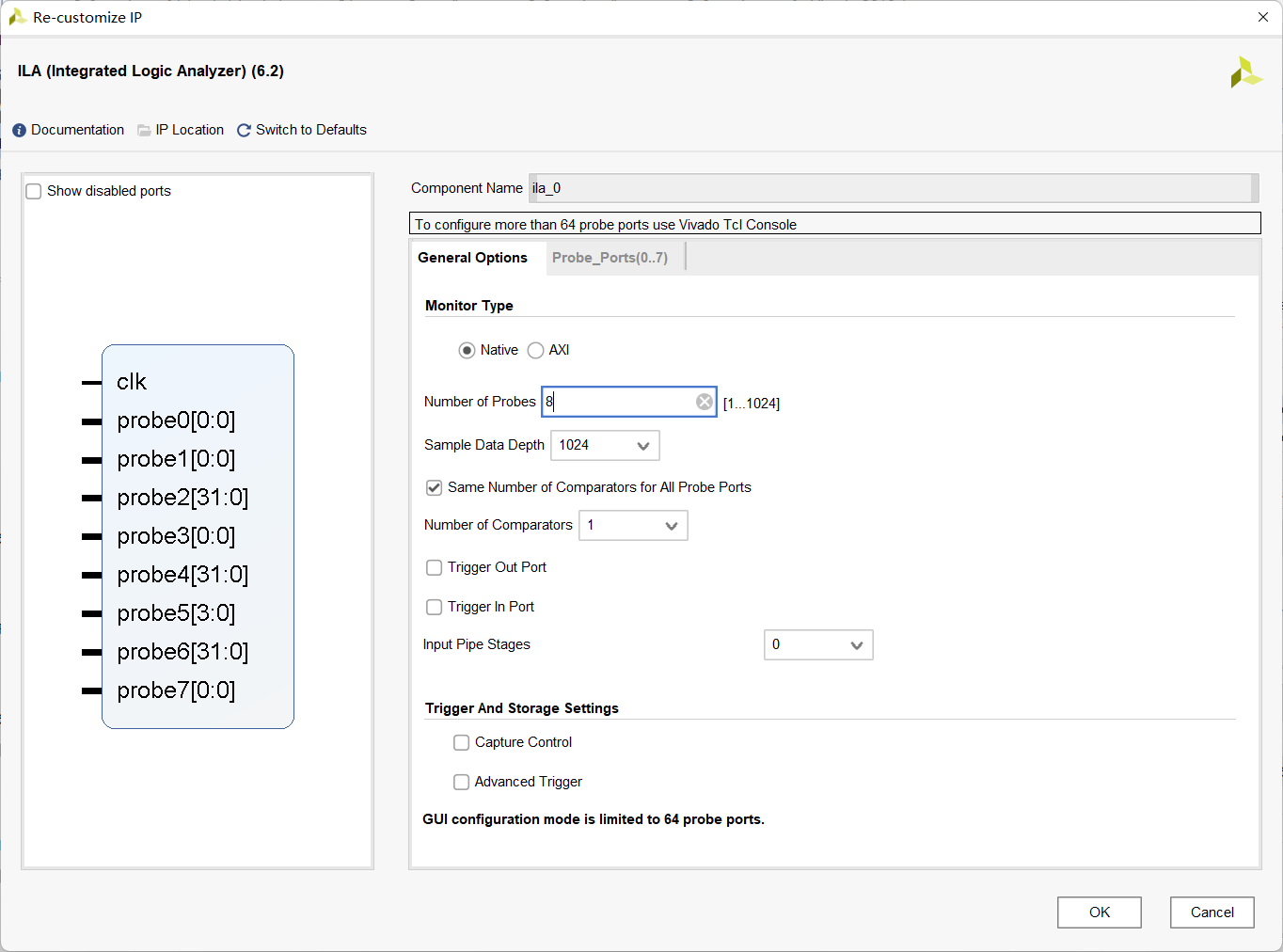
然后在bram_wr文件下,添加ila模块并将其实例化
ila_0 ila_inst (//ila部分,用于DEBUG,不调试可忽略这部分
.clk(ram_clk), //时钟
.probe0(ps_rd_start), //ps端开始读取标志
.probe1(pos_start_rd), //pl端开始操作
.probe2(ram_wr_data), //pl端写入bram数据
.probe3(ram_en), //bram enable
.probe4(ram_rd_data), //pl端读bram数据
.probe5(ram_we), //bram write enable
.probe6(ram_addr), //bram address
.probe7(flow_cnt) //状态机
);之后按照流程,跑出比特流,导出硬件,并在SDK中进行Program FPGA(PS端与PL端同时调试的要求),然后运行,注意,这里运行需要Run as Launch at Hardware(System Debugger),才能继续进行调试,之后在Vivado中,打开Hardware Manager,刷新设备,这时可以看到设备下有一个ILA核心,这时可以添加需要监视的端口,并在右下的窗口中指定端口电平变化触发的条件,并运行等待触发,之后可在Waveform窗口中得到以下结果
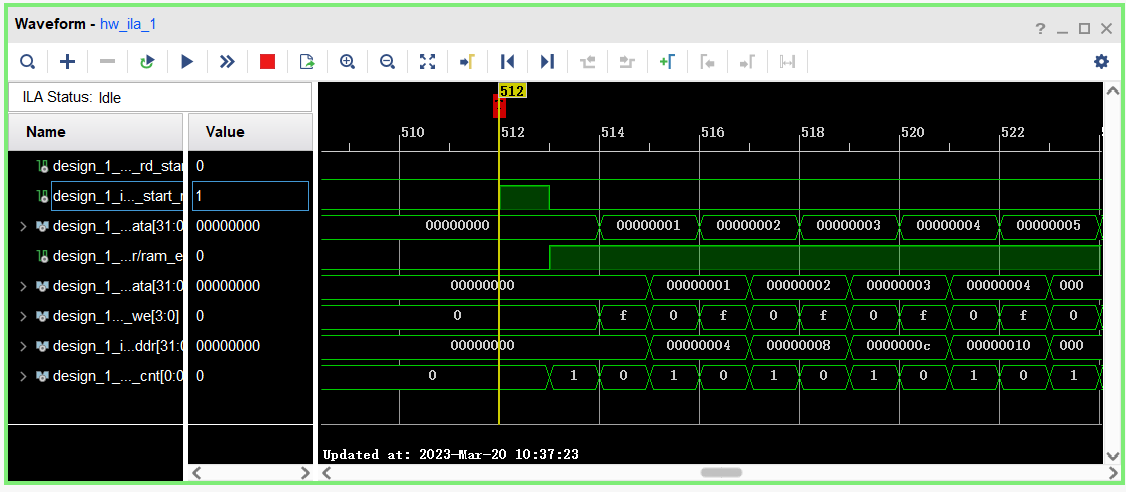
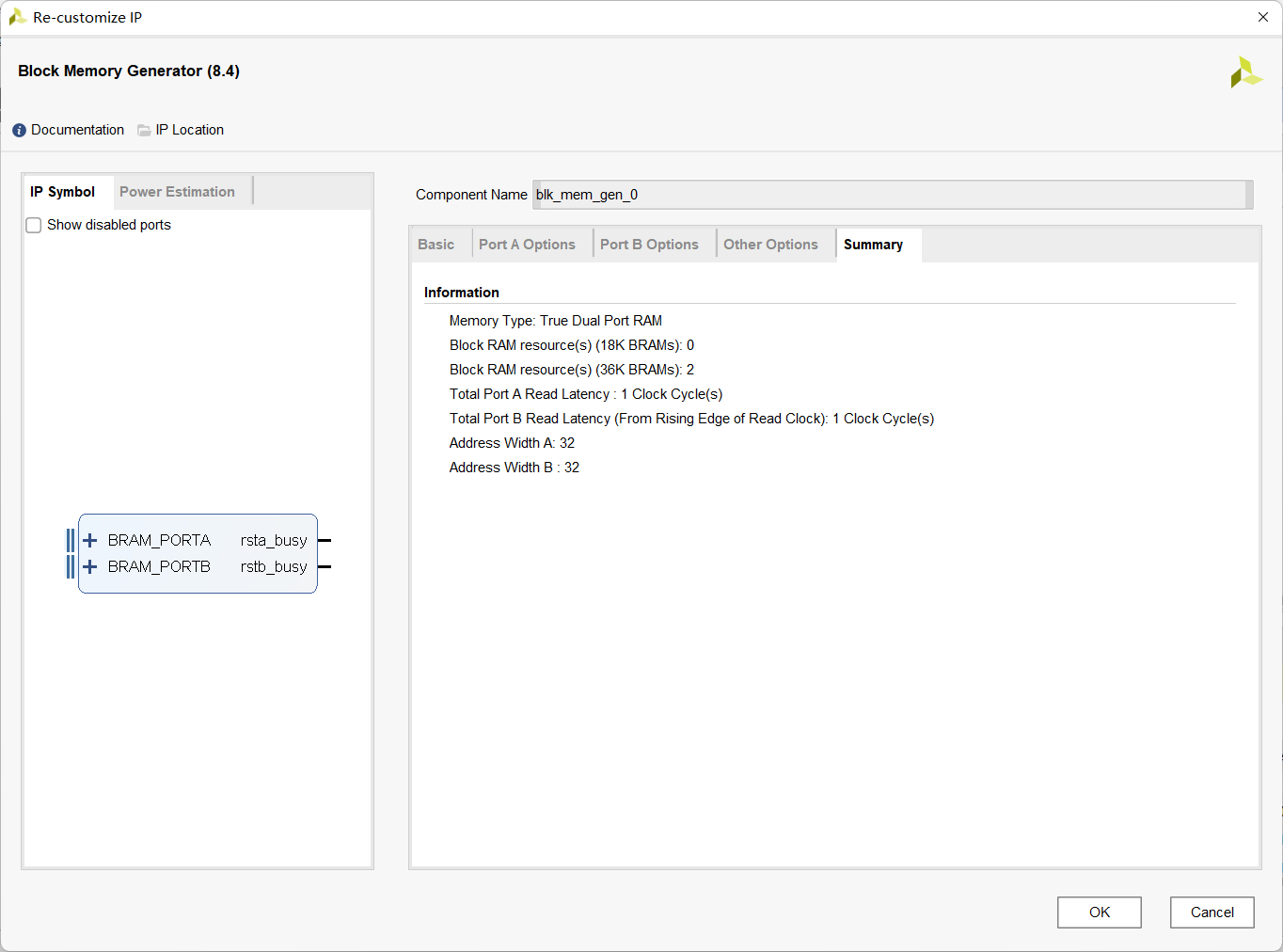
我们发现BRAM的写入数据比读出数据明显快了一个电平,也就是说,原作者代码中读出的数据,实际是BRAM上一个地址中的内容,而在Vivado中,Block Memory Generator也有对此的描述,会延迟一个时钟周期。
而作者原代码如下,读取和写入同时发生,这就是为什么我们使用原作者的代码时,PS端不管写入什么数据,永远只能得到一个递增数列结果的原因,因此,需要在原代码的状态机中,添加一个延迟,消耗一个时钟周期,以此读取正确的BRAM输出的内容
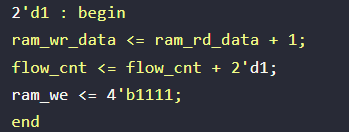
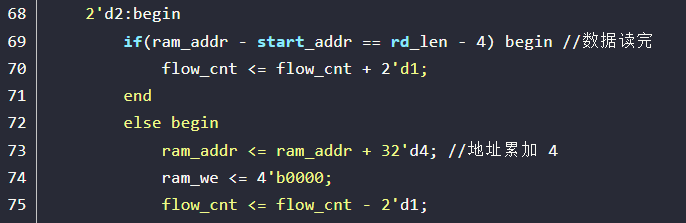
然后我们再看到原作者的代码中,还有一个致命错误,如图,在这个状态机中,当写入到BRAM指定末地址时,没有将bram的write enable信号拉低电平,因此,PL端在下一次运行时极有可能写入上一次的读取的内容,从而影响结果
总结
本文通过学习一篇来自CSDN的文章并且修正其中的错误,达成了PL端与PS端通过BRAM传输数据的目的。
所见非所得,在试验自己的代码时,一定要使用多组测试数据,必要时使用ILA进行debug工作,才能更好地完成在FPGA开发板上的工作。